
Avx throttling (Part I) - UPDATED
SIMD instruction
Modern CPUs contain so-called vector extensions or SIMD instructions. SIMD stands for Single Instruction Multiple Data. For x86-64 CPUs example of such instructions would be (in historical order): MMX, SSE, SSE2, SSE3, SSSE3, SSE4, SSE4.2 and most modern additions to the family: AVX, AVX2, AVX512. The idea behind those extensions is the possibility to process multiple inputs or vector of data in a single operation. This kind of processing is very useful in numerical computations, computer graphics, neural networks. All applications which are doing repetitive mathematical operations over a big set of data like matrices or pixel streams. Regular non-vector x86-64 instructions usually take 64bit input operands so, for example, can add 64bit numbers using a single instruction. Vector extensions allow to increase that to 128bit (SSE), 256bit (AVX, AVX2) or even 512bit (AVX512) so respectively 2, 4 and 8 64bit numbers in one go. Few examples below:
/* Adding 2 64bit numbers with SSE2: */
__m128i _mm_add_epi64 (__m128i a, __m128i b);
/* Adding 4 64bit numbers with AVX2: */
__m256i _mm256_add_epi64 (__m256i a, __m256i b);
/* Adding 8 64bit numbers with AVX512:*/
__m512i _mm512_add_epi64 (__m512i a, __m512i b);
Of course, there is much more than just adding integers. In fact the number of instructions goes into hundreds. There is a great interactive tool from Intel, with a full list of intrinsics for SIMD instructions.
Vector extensions have also few disadvantages:
- works well with number crunching, but not with branches (conditions). Can accelerate matrix multiplication, but not that much file compression or code compilation
- data needs to be aligned (so not applicable to Packet Descriptors from previous posts, which were placed back to back or packed)
- not directly supported by
C++- requires specific data types (__m512i,__m256i,__m128ietc.) and intrinsics (_mm256_add_pd,_mm_add_epi16etc.) - can cause CPU clock to drop by almost 40%!
AVX and CPU frequency
As it turns out when using AVX2 and AVX512 extensions CPU clock can go down by a few hundred MHz. Most powerful vector instructions lits regions of silicon in CPU that are usually not powered and draws so much current, that CPU needs to lower clock to keep within its Thermal Design Power. While internal details are complex and not fully available outside Intel labs, few things are known. Not every AVX2/AVX512 instruction has this limitation, some can be executed at full speed indefinitely. And it is not enough to run single “heavy” instruction to cause throttling. More details can be found in Daniel Lemire’s blogpost. The degree of throttling is specified in CPU documentation and impacts also Turbo frequencies. Here are examples of two medium-range server CPUs.

Xeon Gold 6248 (Cascade Lake):

At least since Skylake CPU clock is set for each core separately, so if one physical core is throttled it will not affect other physical cores. Of course logical aka. HyperThreading cores will be affected hence the ideas like AVX aware schedulers and tracking AVX usage in Linux kernel.
Practical implications
To check to what degree AVX throttling can impact performance we need to benchmark workload that can be implemented using both regular and AVX instructions. As an example of such workload, I have prepared rather a dummy but “good enough” code doing some math on a vector of floats. I was not using SIMD intrinsics but rather relied on compiler doing automatic vectorization. There are four versions of number-crunching function: default x86-64, AVX, AVX2 and AVX512 created using target attribute:
void float_math_default(NumType* buffer);
__attribute__ ((__target__ ("avx")))
void float_math_avx(NumType* buffer);
__attribute__ ((__target__ ("avx2")))
void float_math_avx2(NumType* buffer);
__attribute__ ((__target__ ("avx512f,avx512cd,avx512vl,avx512bw,avx512dq")))
void float_math_avx512(NumType* buffer);
Implementation can be found in float_crunching.cpp and results in float_crunching.txt.
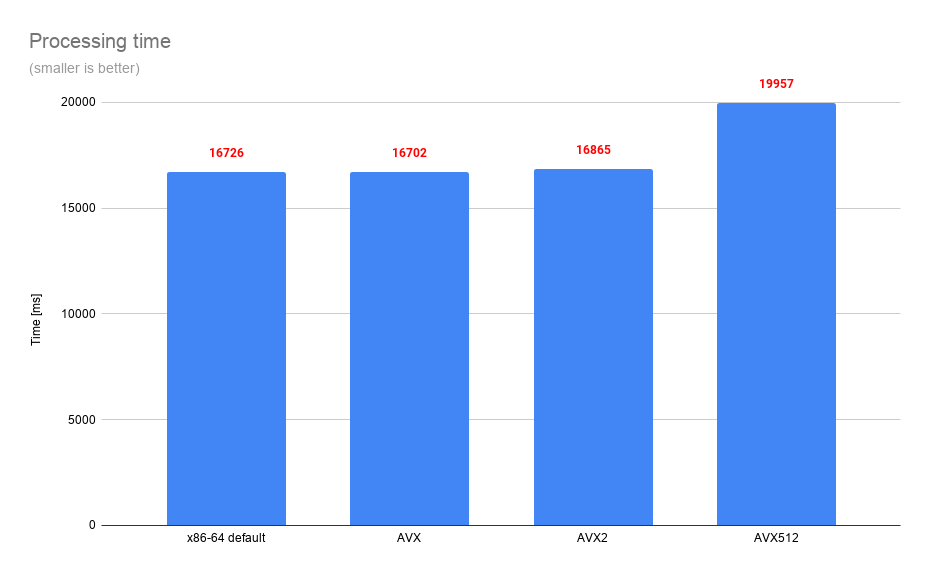
Measurements show that AVX512 variant is almost 20% slower than any other version! Let’s check then how CPU clocks look for different variants of our code. To make it easier I will pin benchmark to the specific core of CPU and than check clock of that core using Intel tool called turbostat.
| Variant | MHz |
|---|---|
| x86-64 | 3100 |
| AVX | 3100 |
| AVX2 | 3100 |
| AVX512 | 2600 |
To no suprise, AVX512 implementation has almost 20% lower clock, which can be blamed for overall worse performance.

Detecting issue
So far we have worked on synthetic benchmark witch explicit settings for instruction set, but in real-life applications with more complex algorithms, it might not be easy to detect this kind of performance issue. Watching CPU clocks can give some hints, but there are all different reasons why the given core can be clocked lower like thermal issues, Turbo limitations, TDP envelope, etc. But there is a better way! Intel provides two CPU counters measuring the amount of throttling due to running AVX instructions and additional counter measuring general throttling:
- core_power_lvl1_turbo_license
- core_power_lvl2_turbo_license
- core_power_throttle
Level1 and level2 correspond to the degree of throttling. In the CPU clock specifications in the tables above, this corresponds to AVX2 and AVX512 rows. Level2 throttling can only happen when using certain “heavy” AVX512 instructions, while level1 can happen for both “heavy” AVX2 and AVX512. Plain AVX should not cause throttling at all.
It is not clear what is a unit for those counters: time, clock ticks or a number of certain events. But the general rule applies: a higher number means more throttling, zero means no throttling at all.
Here is how to measure those metrics using perf top:
perf stat -e cpu/event=0x28,umask=0x18,name=core_power_lvl1_turbo_license/,cpu/event=0x28,umask=0x20,name=core_power_lvl2_turbo_license/,cpu/event=0x28,umask=0x40,name=core_power_throttle/ ./FloatCrunching 0
and results:
| Variant | lvl1 | lvl2 | throttle | MHz |
|---|---|---|---|---|
| x86-64 | 0 | 0 | 1426 | 3100 |
| AVX | 0 | 0 | 2445 | 3100 |
| AVX2 | 0 | 0 | 0 | 3100 |
| AVX512 | 51770739083 | 0 | 85122 | 2600 |
It is visible how AVX512 implementation of our algorithm triggered Level1 and how that causes general throttling. And we haven’t even reached Level2, which for this particular CPU can lower clock further to 2200 MHz!
Conclusion
Vectorization can be a powerful performance improving tool, but sometimes this comes with a cost. For AVX512 this cost can be surprisingly high and in my projects, I will be much more careful using it. Except for some very specific, narrow use cases, AVX2 or even AVX can provide similar vectorization improvements, while not downclocking CPU and crippling its performance. For now, disabling AVX512 compilation flags by default and enabling those only for specific functions seems like a reasonable solution.
In the next part, I will try to check how bad Level2 throttling can be and show how things can get even worse with glibc interactions.
All code used to write this article can be found, as usual on my GitHub. Compiler used was gcc-9.3 and CPU Xeon Gold 6148.
Update
After bit of critique and bit of suggestions from redditors I have applied few modifications to original code. It seems that code was barely vectorized and throttling completely diminished performance benefits. Proposed modifications:
- use
-ffast-mathwhich allows compiler to use faster but slightly less accurate FP math - do not align
Point structas it may cause memory layout problems for compiler - use
gcc9.3instead of gcc9.2, as it apparently better handles AVX vectorization (not done, apparentlygcc9.3is not that trivial to get for Ubuntu 18.04) - use intrinsics (that would kind of miss the point, throttling would be more expected there)
New set of results:
| Variant | baseline | fast-math | no align | fast-math + no align |
|---|---|---|---|---|
| x86-64 | 16518 | 4997 | 16259 | 10954 |
| AVX | 16487 | 7421 | 16244 | 10954 |
| AVX2 | 16528 | 7319 | 16235 | 3431 |
| AVX512 | 19856 | 3958 | 19441 | 2468 |
Throttling (for fast-math + no align):
| Variant | lvl1 | lvl2 | throttle |
|---|---|---|---|
| x86-64 | 0 | 0 | 1197 |
| AVX | 0 | 0 | 1812 |
| AVX2 | 0 | 0 | 0 |
| AVX512 | 1820071177 | 3743676850 | 322877 |
So even though there is fair share of Level2 throttling, AVX-512 can be fastest out of all implementations. This shows that with proper aproach it can boost performance, but on the other hand when relying on compiler vectorization it is not that easy to do it right. If compiler can silently put “expensive” instructions here and there, giving no benefit, and some throttling than this is something to be aware of. And it is not AVX to blame, but rather way how interactions between compiler and hardware can cause performance issues.
Comments